Near full-RAG quality, far fewer RAG tokens.
Trajbl v0.1 EXP is a new evidence-packing method that sits between retrieval and the LLM. Full-context RAG is the quality ceiling, but production systems pay for every retrieved token. Trajbl turns retrieved context into a short, traceable evidence packet. The current Phase31 benchmark shows 85% fewer tokens, 97% of full-RAG quality retained, and stronger compact answers than LLMLingua-style compression at similar compact budgets.
Public evidence package now available
Review the scoped benchmark summaries, claim ledger, limitations, and controlled demo guide for Trajbl v0.1. Source code remains proprietary; this package contains public evidence only.
Run the real Trajbl method on your own text and watch the token count drop live — then verify the quality in your own LLM. Request access → we approve you → test. It’s a focused demo; for a full evaluation on your data, contact us.

RAG works. It just sends too much.
Modern AI assistants often send large retrieved context blocks to the model just to answer one question. Trajbl v0.1 EXP turns that pile into a compact evidence packet, so the model reads less, costs less, and still sees the proof needed for a strong answer.
Context is the cost.
Every retrieved chunk the model reads becomes recurring token cost, latency, and infrastructure load. Generic compression can reduce the bill, but it can also damage meaning and weaken the final answer.
Keep the evidence. Drop the noise.
Trajbl v0.1 EXP uses a proprietary evidence-selection layer to forward a compact, traceable packet to the LLM. The model gets a short brief instead of a haystack, at a fraction of the token cost.
Near-ceiling quality. Much lower context cost.
Trajbl is not trying to win an unlimited-context contest against full-context RAG. It makes the same RAG workflow more economical: far fewer context tokens, close to full-RAG answer quality, and stronger compact answers than tested compression baselines.
Cost vs quality, at a glance
Full RAG is the quality ceiling, not the economic target. Trajbl v0.1 EXP lands near that ceiling while using a compact packet, then scores above the tested compression alternatives in that same low-token zone.
Compression baseline comparison
Trajbl v0.1 EXP is not a replacement for RAG. It is a measured compact-context layer: in tested evidence-QA setups, it produces stronger compact answers than LLMLingua-family compression baselines.
| Method, Phase31 current benchmark | Raw quality | Quality retained | Token load |
|---|---|---|---|
| Full-context RAG top-12 quality ceiling, expensive context | 0.7225 | 100% | 7,023 / 100% |
| Trajbl v0.1 EXP pool12 best tradeoffBest tradeoff | 0.7041 | 97% | 1,088 / 15% |
| LLMLingua question-aware Microsoft Research family baseline | 0.5872 | 81% | 1,216 / 17% |
| LLMLingua blind compression without question awareness | 0.5390 | 75% | 1,185 / 17% |
| Naive truncation simple cut baseline | 0.6789 | 94% | 992 / 14% |
The headline is not "Trajbl v0.1 EXP beats full RAG." Full RAG is the reference ceiling, not the economic target. The headline is that Trajbl v0.1 EXP keeps near-ceiling quality while cutting token load by 85% and producing stronger compact answers than LLMLingua-style compressors.
Matched against a trained SOTA pruner
Naver Provence is the strongest open evidence pruner — a trained ~300M-parameter model. With zero training, zero model and zero GPU, Trajbl v0.1 EXP holds parity on evidence coverage and wins outright on some question types.
| Metric, Trajbl vs trained Provence | Trajbl v0.1 EXP | Provence |
|---|---|---|
| Evidence recall MultiSpanQA coverage | 0.93 | 0.90 |
| Coverage at matched budget Croatian evidence frontier | 0.92 / 338w | 0.91 / 368w |
| Yes/no questions experimental Plan-A bridge+0.19 to +0.30 | 0.71 | 0.52 |
| Cost to run operational footprint | no training / model / GPU | trained 300M model |
On overall answer quality the trained model is marginally ahead — but Trajbl v0.1 EXP reaches that level with none of its training, model or GPU cost, never prunes to an empty context, and runs on any language out of the box.
Phase31 measures how much RAG quality Trajbl preserves at a fraction of the token load.
The current benchmark uses the same 109-task FairV4 scope and the same top-12 retrieval pool for each arm. Full-context RAG is treated as the quality ceiling; Trajbl v0.1 EXP is evaluated as the economical evidence-packing layer that runs between retrieval and generation.
Quality retained, same retrieval pool
Tokens sent to the model
Early cross-document signal: cheaper multi-source evidence
Validated through multiple lenses
The same efficiency pattern shows up across blind judging, objective F1, and cross-document probes.
1 — Current OpenAI blind judge
Phase31 shows Trajbl v0.1 EXP at 97% of full-RAG quality, with 85% fewer tokens and a +20% lift over question-aware LLMLingua.
2 — Objective English F1
On English multi-hop QA, Trajbl v0.1 EXP scores 0.4001 F1 vs 0.2329 for LLMLingua-2 and 0.1971 for LongLLMLingua-7B.
3 — Cross-document potential
Early cross-document testing shows near full-RAG quality with 82% fewer tokens and a large lead over question-aware LLMLingua.
The RAG context-reduction landscape, in plain terms.
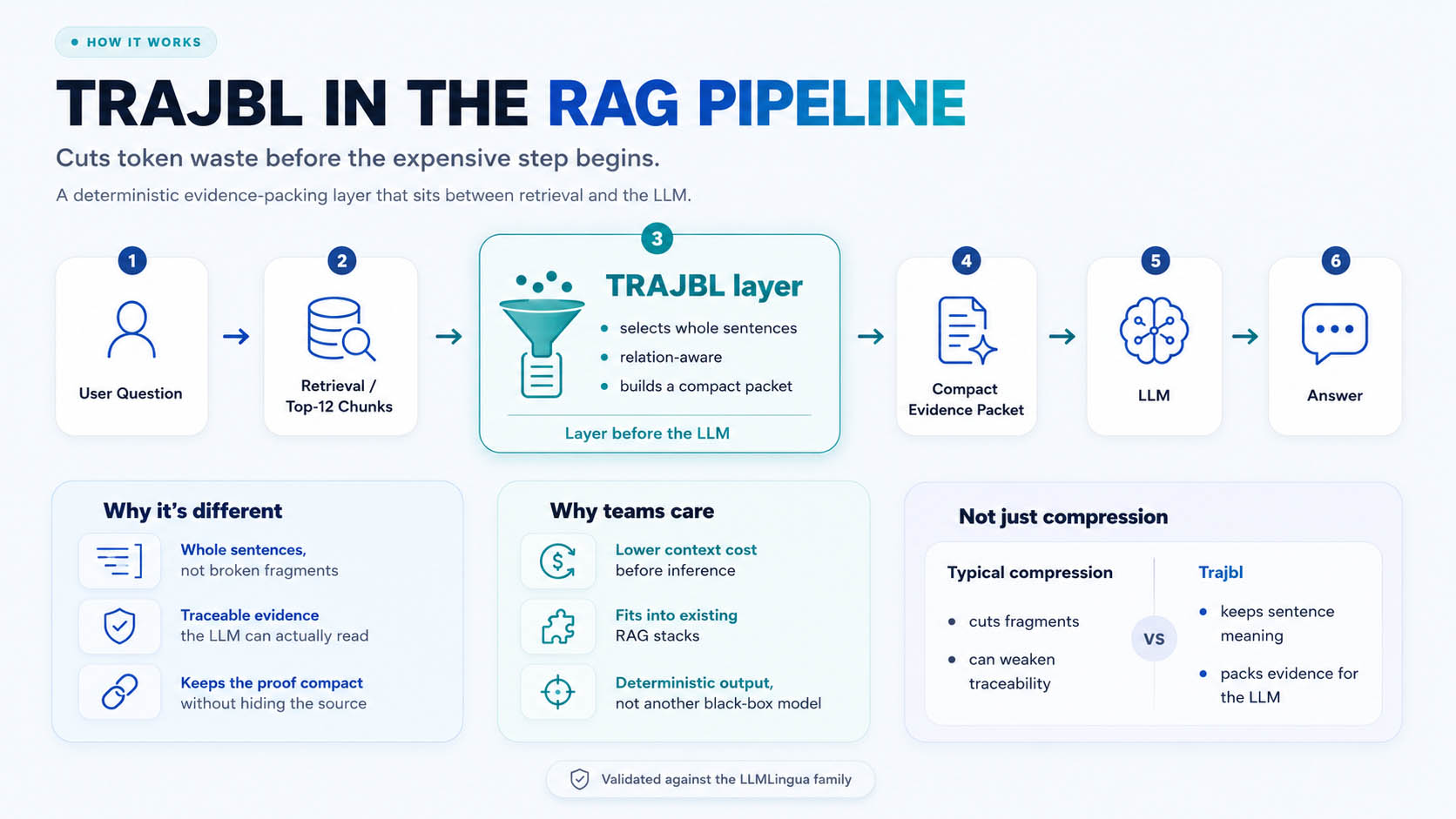
Trajbl v0.1 EXP is not another retriever, LLM, or RAG framework. It is the evidence-packing layer after retrieval and before generation: closer to sentence-level pruning than to generic prompt compression.
| Fit | Option | Category | Why teams use it | Tradeoff for Trajbl's job |
|---|---|---|---|---|
| 1 | Trajbl v0.1 EXP evidence-packing layerExact target | Deterministic sentence selection Whole, traceable evidence sentences selected after retrieval. |
Designed for lower RAG token cost, readable evidence packets, reproducible behavior, and zero model/GPU overhead. | Available through partnership discussions today; technical deep-dive and deployment details available directly with the Trajbl team. |
| 2 | Provence / XProvence trained evidence pruner | Sentence-level context pruning A public trained-model direction closest to Trajbl's evidence-pruning role. |
Strong external analogue for teams looking at sentence-level RAG pruning and reranking. | Requires a trained model and has less transparent decision logic than deterministic evidence rules. |
| 3 | Cohere, Jina, Voyage and other rerankers commercial or local reranking | Chunk or document reranking Reorder retrieved candidates and pass only the best ones forward. |
Mature, easy to deploy, and often a strong production baseline for improving retrieval quality. | Usually ranks chunks, not sentence-level evidence packets; auditability depends on the surrounding system. |
| 4 | LLMLingua / LongLLMLingua prompt compression baselines | Token or span compression Reduce prompt length by pruning parts of the input context. |
Recognized open-source baseline family for prompt compression and long-context reduction. | Can fragment evidence; in Trajbl's tested evidence-QA setup, Trajbl produces stronger compact answers. |
| 5 | LangChain Contextual Compression framework pattern | RAG orchestration A way to combine retrievers, compressors, filters, rerankers, and LLMs. |
Fast path for prototyping and integrating existing compression or reranking components. | Not one algorithm; quality depends on which compressor or reranker is plugged in. |
| 6 | LlamaIndex Node Postprocessors framework pattern | RAG postprocessing toolkit Filter, reorder, or transform retrieved nodes before answer generation. |
Practical ecosystem for teams already building RAG pipelines in LlamaIndex. | Useful infrastructure, but not equivalent to Trajbl unless a Trajbl-like selector is implemented or plugged in. |
| 7 | Full-context RAG quality reference | Baseline architecture Send most or all retrieved context to the LLM. |
Often the quality ceiling when cost, latency, and context-window pressure are acceptable. | Expensive at scale; every retrieved token becomes recurring inference cost. |
Lower token cost, stronger compact answers, production-friendly RAG economics.
The core advantage is simple: Trajbl v0.1 EXP cuts expensive context before the LLM reads it, while preserving a traceable evidence packet for the final answer.
85% lower token load
Phase31 shows 1,088 Trajbl v0.1 EXP tokens versus 7,023 for full-context RAG, while retaining 97% of full-RAG judged quality in that benchmark.
Better than compression baselines
In the tested setup, Trajbl v0.1 EXP scores +20% over question-aware LLMLingua, +31% over blind LLMLingua, and +103% over LongLLMLingua on the English F1 benchmark.
Deterministic & model-free
No training, no GPU, runs on CPU. The same input always yields the same output — exactly reproducible, and cheap to operate at scale.
Auditable by design
Every sentence forwarded is verbatim and traceable to its source — a natural fit for regulated domains like healthcare, finance, and law.
Promising on multi-source evidence
Cross-document testing shows 82% fewer tokens, 97% of full-RAG quality retained, and a +95% lift over question-aware LLMLingua.
Model- & vendor-agnostic
Works in front of any LLM and any retrieval stack. No lock-in, no fine-tuning — it slots into systems teams already run.
Language-independent, zero-training
Proven on English (+0.167 F1 vs LLMLingua) and Croatian (+0.19) with no language-specific tuning. Works on a new language instantly — no data, no retraining.
Never returns empty
Even trained pruners can cut away all context on hard inputs. Trajbl always returns a traceable evidence packet — a safety property for production and regulated use.
On par with a trained SOTA pruner
Matches Naver Provence on evidence coverage (recall 0.93 vs 0.90) — and wins yes/no questions — while using zero training, model or GPU.
Built for auditability today, with a clear path to higher accuracy.
What makes Trajbl different.
Core today, Pro next.
RAG token spend is becoming infrastructure spend. Trajbl v0.1 EXP cuts it without giving up answer quality.
As AI assistants move into production, context tokens become a recurring infrastructure cost on every query. Trajbl v0.1 EXP cuts that load before generation starts: fewer tokens sent to the model, less wasted context, and compact answers that benchmark stronger than generic compression.
Recurring token savings
The benefit lands on every query, so value scales directly with customer AI usage.
Horizontal across industries
Search, support, biomed, legal, finance — anywhere evidence-grounded answers are needed.
Baseline edge
Current benchmarks show Trajbl v0.1 EXP scoring above Microsoft LLMLingua-family baselines at compact token budgets.
How this all works — explained for anyone.
No jargon. Here's how AI assistants answer questions today, the world-standard way, and where Trajbl v0.1 EXP quietly changes the economics.
You ask a question
A large language model (LLM) — the technology behind ChatGPT-style assistants — is great at writing answers, but on its own it doesn't actually know your company's documents. So it can't reliably answer questions about them.
The system fetches documents (this is "RAG")
The world-standard fix is called RAG — Retrieval-Augmented Generation. Before answering, the system searches your files and grabs the chunks that look related to the question, then hands all of that text to the model as background reading. This is now the default way serious AI products answer from private data.
The catch: you pay for every word
The model is billed by the token (roughly, a piece of a word) for everything it reads. RAG tends to grab a lot of text to be safe — most of which is irrelevant. So you pay for piles of noise, answers get slower, and the few sentences that truly matter get buried.
The usual shortcut: squeeze the text
The standard way to cut that cost is "context compression" — tools that shrink the text by deleting words they predict are unimportant. It saves money, but it chops sentences into fragments and often loses the meaning: a "not" goes missing, a number drifts from its label, and the answer quietly degrades.
Where Trajbl v0.1 EXP fits in
Trajbl v0.1 EXP slots in right after the documents are fetched and before the model reads them. Instead of squeezing text blindly, it builds a short, traceable evidence packet for the question. The model gets a clean brief; you pay for a fraction of the words; and the answer benchmarks stronger than the squeeze-the-text shortcut.
Let's talk.
Trajbl v0.1 EXP is a working evidence layer for teams that need to cut RAG token cost without losing traceability. If you're an investor, design partner, or a team running AI on your own documents, we can walk through the benchmark detail and pilot path.