Claw, Claude Code, Codex-like agents
A coding agent often sends repo files, memory, tool notes, and conversation history to the LLM. Trajbl cuts that packet before the model call, so the same task can burn fewer paid input tokens.
Trajbl is a post-retrieval context compressor for RAG, agent memory, and knowledge-base chat. It keeps the evidence sentences that matter and sends a smaller packet to the LLM.
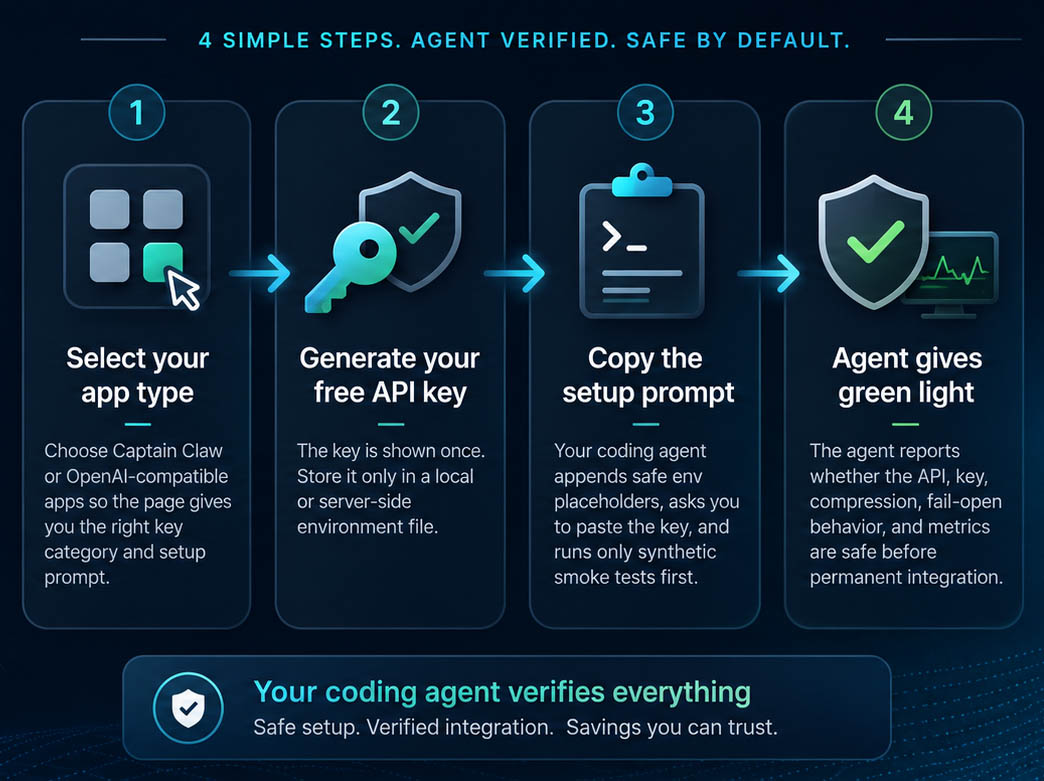
The free pilot flow is intentionally simple: create a key, copy a setup prompt into your coding agent, and let the agent run safe synthetic checks before enabling anything permanent.

On controlled public benchmark suites including LongBench-style multi-hop QA and WixQA-style support workloads, Trajbl showed stronger quality-per-token than LLMLingua2 while remaining CPU-first and model-free.
Most AI apps charge, directly or indirectly, for tokens. Tokens are the pieces of text sent to and from the model. When Claw-like agents, coding assistants, Obsidian vault chat, Open WebUI, AnythingLLM, PrivateGPT, or enterprise RAG tools send huge context packets, you pay for that extra text. Trajbl reduces that packet before the expensive model call.
A coding agent often sends repo files, memory, tool notes, and conversation history to the LLM. Trajbl cuts that packet before the model call, so the same task can burn fewer paid input tokens.
These tools retrieve notes, PDFs, transcripts, and docs. Trajbl sits after retrieval and sends only the strongest evidence sentences instead of dumping every retrieved chunk.
If your app normally sends about 10,593 context tokens, the measured Trajbl path sent about 1,313. That is roughly 88% fewer input tokens before the model call.
The LLM still gets the important evidence, but you stop paying it to reread irrelevant surrounding text on every request.
Trajbl plugs in after your existing RAG, agent memory, or vault retrieval step and packs the retrieved top-k context before it reaches the LLM.
It keeps readable source sentences instead of broken token fragments, which makes the final packet easier to inspect and audit.
No model server, no GPU, no training loop. The benchmarked Trajbl path runs locally as a lightweight preprocessing layer.
Designed for knowledge-base chat, agent memory, Claw-like developer agents, and private RAG systems where context cost and evidence control matter.
We are preparing plug-and-play pilots for AI agents, knowledge-base chat, and private memory systems. The public demo link can remain offline while benchmark validation continues.